Blog
Best SaaS Spend Management Software for Finance & IT Teams in 2026
Table of Contents ToggleWhat Is OpenAI API Pricing?Usage-Based Pricing vs. Subscription...
Back
Back
Search for Keywords...
Blog
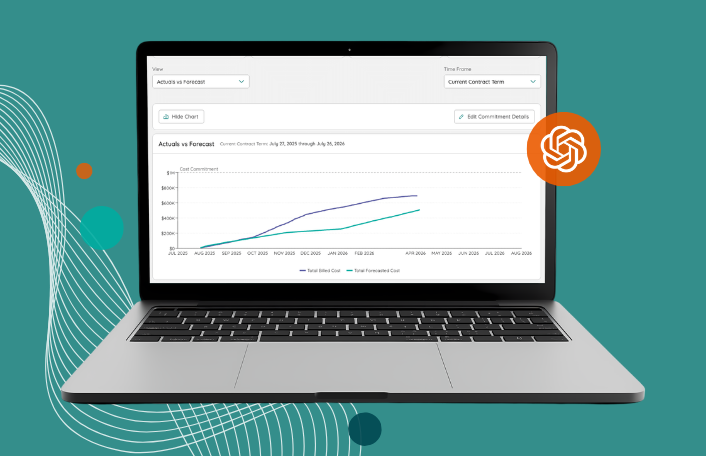
Table of Contents

OpenAI API costs an organization $384,500 annually on average, according to Zylo data, as of April 2026. Considering AI-native application spend soared 108% in 2025, budget pressure will only continue to increase.
The primary challenge is cost variability, as OpenAI API spend can fluctuate significantly based on how applications behave in production. Model selection, token volume, and workflow design also influence cost, meaning the same use case can produce vastly different outcomes.
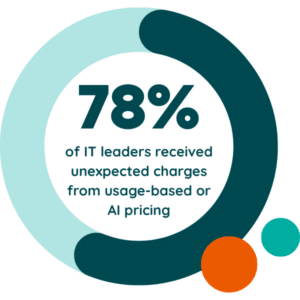 As organizations adopt AI and shift toward consumption-based pricing, managing this variability requires a shift from static budgeting to continuous consumption cost management. According to Zylo’s 2026 SaaS Management Index, 78% of IT leaders experienced unexpected charges tied to AI and consumption, and 60% lack full visibility into generative AI usage.
As organizations adopt AI and shift toward consumption-based pricing, managing this variability requires a shift from static budgeting to continuous consumption cost management. According to Zylo’s 2026 SaaS Management Index, 78% of IT leaders experienced unexpected charges tied to AI and consumption, and 60% lack full visibility into generative AI usage.
This is where consumption cost management for AI and API-driven spend becomes critical. IT, SAM, and FinOps teams need to connect OpenAI API usage to cost, monitor how consumption impacts spend, and take action before overages occur.
In this blog, I’ll break down OpenAI API pricing and cost drivers, best practices to optimize AI spend, and how Zylo helps IT, SAM, FinOps leaders control consumption costs.
OpenAI API pricing is a consumption-based pricing model where organizations are charged based on how application, agent, or workflow usage translates into cost. Instead of fixed licenses, pricing is tied to measurable units such as tokens, image generation, and other metered activity.
Each API request generates consumption data—such as input tokens, output tokens, or tool usage—which is then mapped to cost based on the model and pricing tier. This structure directly links how applications use the OpenAI API to overall spend.
For IT, SAM, and FinOps teams, OpenAI API pricing shifts cost management from tracking licenses to understanding how consumption drives financial impact.
OpenAI API’s pricing model differs significantly from traditional subscription pricing used in SaaS and some LLM tools.
| Subscription (SaaS) Pricing | OpenAI API (Consumption) Pricing |
|---|---|
| Spend grows with number of users (seats) | Spend grows with usage (input tokens, output tokens, image generations, and other metered activity) |
| Costs are relatively predictable | Costs fluctuate based on usage patterns |
| Budgeting is done annually | Budgeting requires continuous monitoring |
| Governance happens at renewal | Governance must happen in real time |
| Usage tied to human activity | Usage driven by humans and automation (agents, workflows) |
| Clear unit (per user) | Multiple units (tokens, image generations, etc.) |
AI-driven applications introduce a different cost dynamic. OpenAI API consumption can be generated continuously by applications and workflows, often without direct user interaction. As a result, spend can increase even when headcount remains unchanged.
OpenAI API pricing connects consumption directly to cost. Managing it effectively requires understanding how application behavior drives spend across models, workflows, and teams.
In my experience, small changes in how applications are built or scaled can significantly impact total spend. The same application can produce very different costs depending on:
Architectural decisions—such as how workflows are structured or how data is passed to the API—directly determine how consumption translates into cost.
As a result, the cost model behaves more like cloud infrastructure (IaaS) than traditional SaaS. Costs are dynamic, distributed across teams, and influenced by both engineering decisions and usage patterns. In addition, new modules introduce higher pricing and more complexity.
OpenAI API pricing varies by model, with costs determined by how each model processes input and generates output. Different models charge different rates per token, which directly impacts how consumption translates into total cost.
The table below outlines how OpenAI API model pricing differs across tiers, as of April 23, 2026. While exact rates may change, the cost structure and tradeoffs remain consistent.
| Model Type | Model Name | Input Cost | Output Cost | Tradeoffs | Typical Use Case |
|---|---|---|---|---|---|
| Flagship | GPT-5.4 | Per 1M tokens
$2.50; cached input $0.25 |
Per 1M tokens
$15.00 |
Highest accuracy and reasoning, but most expensive | Complex reasoning, coding, multi-step workflows |
| Flagship | GPT-5.4 mini | Per 1M tokens
$0.75; cached input $0.075 |
Per 1M tokens
$4.50 |
Balanced cost and performance | Chat, automation, general-purpose apps |
| Flagship | GPT-5.4 nano | Per 1M tokens
$0.20; cached input $0.02 |
Per 1M tokens
$1.25 |
Lower accuracy, but highly cost-efficient at scale | High-volume, simple tasks |
| Multimodal | GPT-realtime-1.5 | Audio: $32, Audio cached: $0.40
Text: $4, Text cached: $0.40 Image: $5, Image cached: $0.50 |
Audio: $64, Text: $16 | Low latency for real-time use, but higher cost variability with continuous interactions | Real-time chat, voice assistants, and interactive applications |
| Multimodal | GPT-image-2 | Image: $8, Image cached: $2
Text: $5, Text cached: $1.25 |
Image: $30 | High-quality image generation, but higher cost per request and scaling with usage | Image generation, creative workflows, and visual content creation |
| Embedding | text-embedding-3-large | Very low | N/A (input only) | No generation capability; optimized for retrieval | Search, clustering, semantic indexing |
Source: OpenAI
Each model tier reflects a tradeoff between cost, performance, and efficiency. Selecting the right model determines how much consumption is required to complete a task—and therefore how much it costs.
Lightweight models (often labeled mini or nano) are typically the lowest-cost option based on price per token.
They are best suited for:
Lower per-token pricing reduces cost at the unit level, but total cost still depends on how many tokens and requests are required to complete a workflow.
Model selection influences OpenAI API costs across multiple dimensions:
A lower-cost model that requires multiple requests can generate higher total spend than a higher-capability model that completes the task in a single step. Evaluating OpenAI API pricing requires focusing on cost per outcome, not just cost per token.
KEY TAKEAWAY
OpenAI API model pricing influences how efficiently consumption converts into cost. Selecting the right model requires evaluating total cost per outcome, not just price per token.
OpenAI API pricing is driven by tokens, which determine how much data is processed in each request and how that consumption translates into cost. Every interaction with the OpenAI API—whether generating text, embedding data, or running a workflow—consumes tokens that are billed based on how they are used.
Understanding how tokens work is essential because even small increases in token volume can significantly impact total OpenAI API costs at scale.
A token is a unit of text that the model processes when handling a request and can represent:
In practical terms:
Each token processed contributes to the total cost. As token volume increases, so does spend.
More text = more tokens = higher cost
OpenAI API pricing separates tokens into input tokens and output tokens, and both contribute to cost.
Output tokens are often priced higher than input tokens. As a result, longer responses can increase total cost faster than expected.
Each request typically includes both input and output tokens, so I recommend teams understand how both contribute to overall spend.
Token-based pricing leads to cost variability because token volume changes based on real-world application behavior.
Common scenarios that increase token-driven costs include:
KEY TAKEAWAY
OpenAI API pricing is directly tied to token volume. Managing cost requires controlling how tokens are generated across inputs, outputs, and workflows as usage scales.
OpenAI API costs are calculated by combining token consumption, model pricing, and request volume. Each API call generates measurable consumption, which is then translated into cost based on pricing rates.
At a basic level, OpenAI API pricing follows a consistent formula.
Total Cost = (Input Tokens × Input Price) + (Output Tokens × Output Price)
To apply this formula in practice:
Assume you’re using the GPT-5.4 model with approximate pricing:
Usage per request:
Estimated cost per request:
Now scale that:
👉 Estimated daily cost ≈ $543.75
👉 Estimated monthly cost (20 business days) ≈ $10,875
👉 Estimated annual cost (250 business days) ≈ $135,973.50
Using the same pricing model:
Usage per request:
Estimated cost per request:
Now scale that to 10,000 documents processed per month
👉 Estimated monthly cost ≈ $165
👉 Estimated annual cost ≈ $1,980
OpenAI API cost estimates often underrepresent total spend because they assume stable usage patterns. In production, consumption changes over time.
Common gaps include:
Each of these factors increases total consumption, which directly increases cost.
OpenAI API costs are difficult to predict because consumption changes continuously as applications scale, evolve, and expand across the organization. Even with a clear pricing model, small shifts in how the API is used can lead to significant changes in total cost.
Cost variability is driven less by pricing complexity and more by how consumption behaves in production environments.
OpenAI API consumption is often fragmented across applications, environments, and providers, making it difficult to build a complete view of how cost is generated.
Common sources of variability include:
Minor adjustments to application behavior can significantly impact cost, such as:
Each change can increase token consumption, which increases cost. These adjustments are often incremental, but their impact compounds at scale.
OpenAI API costs do not scale linearly with headcount. Consumption is driven by how applications operate, not just how many users are involved.
Often, I’ve found cost increases are driven by:
Because these systems generate consumption independently, cost can increase without a clear signal at the user level.
Many organizations lack a clear connection between OpenAI API consumption and financial impact. Common challenges include:
Without this connection, teams often identify cost increases after they occur, limiting their ability to respond effectively.
KEY TAKEAWAY
OpenAI API costs are hard to predict because consumption is dynamic, distributed, and often disconnected from clear cost visibility. Managing this variability requires connecting consumption to cost across applications and teams.
OpenAI API costs are driven by how applications, agents, and workflows generate and scale consumption across workflows, models, and systems. In addition to tokens, costs can also be influenced by tools, storage, and multimodal inputs.
Primary cost drivers include:
Understanding these drivers is critical because they determine how consumption translates into cost at scale.
The most direct cost driver is the number of API calls generated by an application, agent, or workflow.
Cost increases when:
For example, a single-step workflow generates predictable cost. A multi-step or agent-based workflow can multiply consumption—and cost—with each additional step. In agent-based systems, these workflows can create feedback loops where each step triggers additional API calls, compounding consumption and increasing cost unpredictably.
Model selection is one of the most important cost drivers. The same workload can produce significantly different spend depending on which model is used and how efficiently it completes the task.
Cost is influenced by:
A higher-capability model may reduce total cost if it completes a task more efficiently, while a lower-cost model may increase spend if it requires multiple requests or additional processing.
Repeated or unnecessary processing is a common source of excess cost, which occurs when:
Each instance increases total consumption, which increases cost. Reducing duplication through caching and workflow optimization can significantly lower OpenAI API spend.
When teams don’t coordinate usage, it can lead to excess and duplicate API calls, which increase costs.
In my experience, uncoordinated usage across teams stems from:
As a result, cost drivers remain hidden until spend has already increased.
To reduce OpenAI API costs, optimize usage by eliminating waste and ensuring every API call delivers value.
I recommend following these best practices:
AI cost optimization focuses on reducing unnecessary consumption while improving cost visibility and control. The goal is to minimize unnecessary token usage, API calls, and processing overhead before costs scale across the organization.
The fastest way to lower OpenAI API costs is to reduce how often the API is called, eliminating avoidable consumption before it scales across the organization.
Many applications generate excess calls through redundant logic or overly granular workflows. Identifying where requests can be consolidated or removed is one of the fastest ways to reduce spend.
To reduce unnecessary API calls in practice:
For example, agent-based workflows often trigger multiple API calls for a single task. Reducing steps or combining operations can significantly lower total usage.
Workflow efficiency is the ability to complete a task using the fewest possible OpenAI API calls and tokens. More efficient workflows reduce the total consumption required per outcome.
Inefficient workflows often rely on multiple sequential requests to complete a single task, increasing both token usage and cost.
To improve OpenAI API workflow efficiency:
Improving workflow efficiency lowers both request volume and token consumption.
Caching is the practice of storing OpenAI API outputs so they can be reused instead of recomputed. It reduces duplicate API calls and unnecessary token consumption.
Repeated processing often occurs in applications that handle similar inputs or re-run workflows, generating new costs for the same work.
To reduce OpenAI API costs with caching:
Caching is especially effective in high-volume or repetitive workflows where the same data is processed multiple times.
Rightsizing means aligning how often and how widely OpenAI API workloads run with actual business needs. Over-scaled workloads can generate excess consumption without delivering additional value.
Applications often run at higher frequency or scale than needed, generating unnecessary consumption over time.
To rightsize OpenAI API workloads and prevent unnecessary cost growth:
Controlling scale ensures consumption grows in line with business demand rather than unchecked activity.
Not all API usage delivers equal value. Aligning consumption with outcomes ensures that OpenAI API costs are tied to meaningful business results.
Some workloads generate high consumption but contribute little to business impact. Evaluating usage through a value lens helps prioritize where cost should be maintained or reduced.
To ensure that OpenAI API costs reflect meaningful output, evaluate:
Batching allows multiple inputs to be processed in a single OpenAI API request, reducing the total number of calls and improving cost efficiency.
Instead of sending individual requests for each task, group them where possible to minimize overhead and optimize how consumption translates into cost.
To apply batching in practice:
Batching is especially effective for background processing and large-scale data workflows, where reducing request volume can significantly lower total cost.
Flex processing involves adjusting when and how workloads run to better align OpenAI API consumption with cost constraints and financial targets.
Workloads that do not require real-time processing are prime candidates for flex processing. By scheduling or deferring non-critical tasks, you can better manage how consumption impacts spend over time.
To implement flex processing:
This approach helps control cost growth by ensuring OpenAI API consumption aligns with financial priorities and timing.
Controlling OpenAI API costs at scale requires a system that connects consumption to cost to understand what is driving spend or take action before overages occur. This approach reflects a consumption cost management framework designed for usage-based pricing models like the OpenAI API.
Follow these six steps:
Establish a centralized view of OpenAI API costs across the organization. When consumption is consistently mapped to cost, visibility becomes actionable, enabling you to:
With Zylo, OpenAI API consumption data is connected to spend in a single system of record, giving IT, SAM, and FinOps teams a continuous view of cost across the organization.
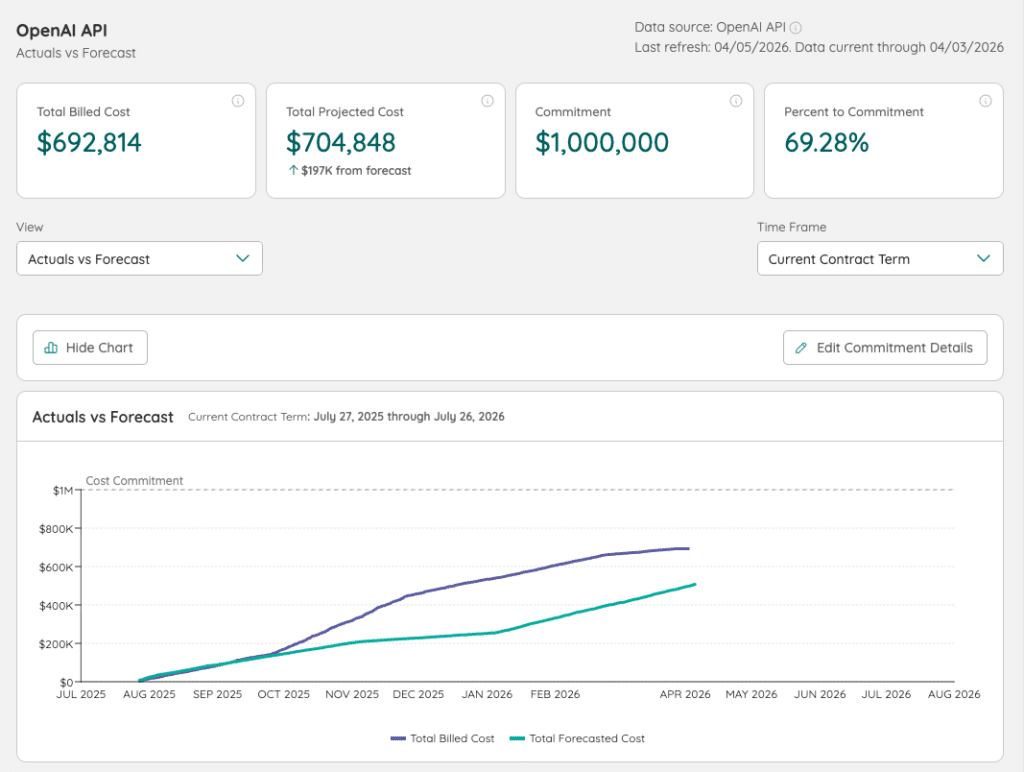
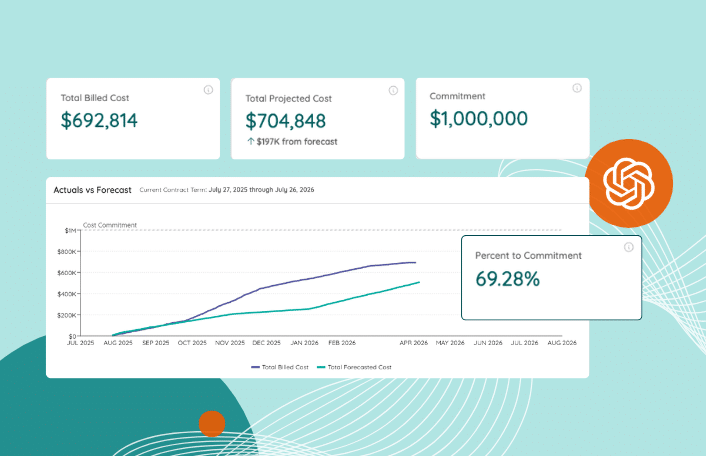
Track how quickly OpenAI API spend accumulates relative to financial targets, so you can take action before exceeding committed spend.
To maintain control, my advice is to:
Using Zylo, SAM and FinOps teams monitor cost burn rates continuously and understand how consumption aligns to financial commitments in real time.
Identify cost anomalies early by defining thresholds and monitoring for unexpected changes in OpenAI API spend.
Start by setting clear alert conditions:
Once thresholds are in place, monitor for signals that indicate abnormal behavior, such as:
When anomalies are detected, act quickly to contain impact. IT and FinOps teams should:
Organizations use Zylo for anomaly detection and alerting to surface unusual usage patterns automatically and enable faster response and tighter cost control.
Forecast future OpenAI API costs based on historical consumption patterns. To improve accuracy:
Forecasting across the contract term helps organizations plan capacity, avoid overages, and optimize financial commitments.
Zylo applies historical consumption data to forecast OpenAI API costs, helping teams anticipate spend and adjust before costs escalate.
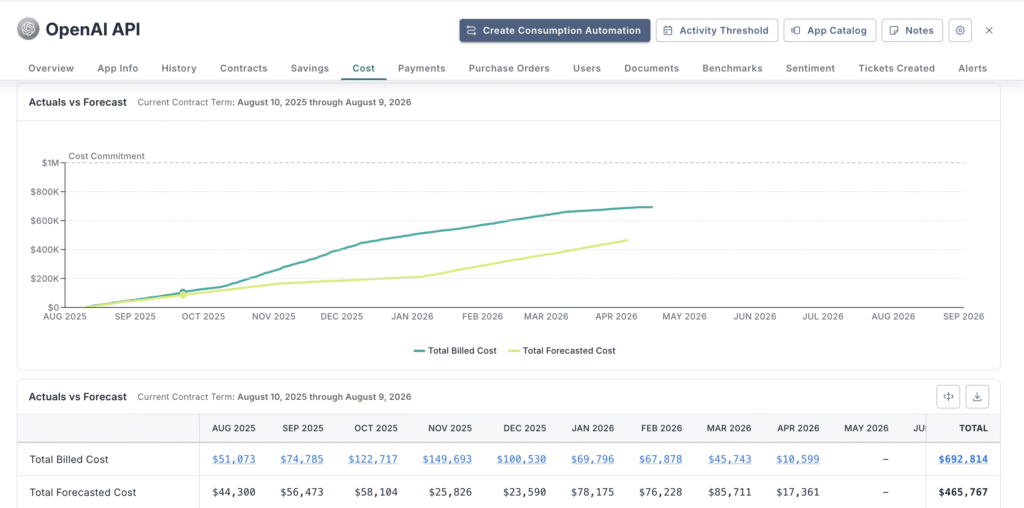
Understand exactly what is driving OpenAI API costs by analyzing usage across key dimensions. You should be able to:
Breaking down usage at this level creates observability, connecting cost to the teams and activities responsible for it.
Zylo delivers this visibility by mapping OpenAI API consumption across models, applications, workspace, and teams, making it easier to prioritize cost optimization efforts.
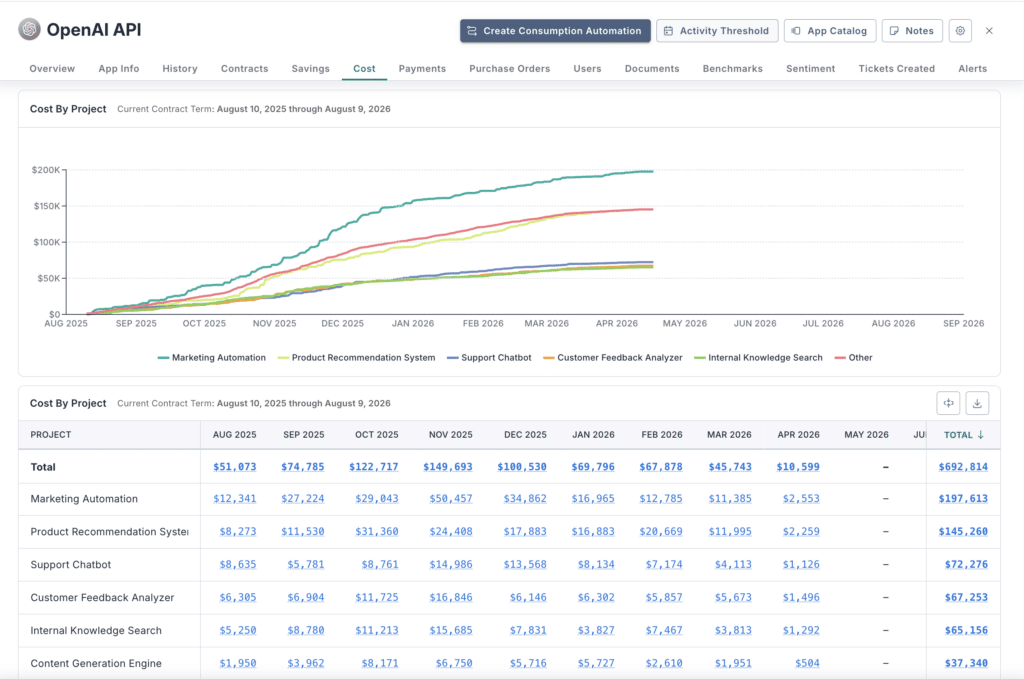
Assign ownership to OpenAI API costs to improve accountability and financial control. You should be able to:
Clear cost allocation ensures that OpenAI API spend is tied to ownership and business outcomes.
With Zylo in place, organizations allocate OpenAI API costs at a more granular level, linking consumption-driven spend to the teams responsible for it.
These capabilities establish a consumption cost management framework that shifts OpenAI API cost control from reactive reporting to proactive financial management.
KEY TAKEAWAY
Controlling OpenAI API costs requires connecting consumption to cost, monitoring spend continuously, and assigning ownership across the organization to maintain financial control at scale.
OpenAI API pricing aligns with other leading LLM providers, including Anthropic and Google Vertex AI, using token-based, usage-driven pricing. Costs are typically based on input tokens, output tokens, and model capability.
While pricing models are structurally similar across providers, total cost varies based on how efficiently each model handles a given workload. To evaluate pricing, it requires looking beyond token rates to understand how usage patterns, workflow design, and model performance impact overall spend.
| Provider | Pricing model | Key Cost Drivers | Notable Differences |
|---|---|---|---|
| OpenAI API | Token-based (input/output) | Model tier, token volume, workflow design | Broad model range, strong ecosystem support |
| Anthropic API | Token-based (input/output) | Context window size, token usage | Larger context windows can increase token consumption |
| Google Vertex AI (Gemini) | Token + compute-based | Token usage, compute resources | Pricing may include infrastructure components |
Token rates alone do not reflect total cost. Actual spend depends on:
Even if you use a lower-cost model, it can generate higher total cost if it requires more steps or retries.
Many organizations use multiple LLM providers across applications, which creates the following challenges:
Without a unified view, teams lack clarity on total AI spend and efficiency.
To evaluate pricing effectively, standardize how costs are measured:
Zylo supports this by bringing OpenAI API and other provider data into a single system, allowing teams to compare costs using consistent metrics and identify the most efficient options.
OpenAI API costs can escalate quickly as usage scales across teams and applications. Without clear visibility into what’s driving spend, overages are often identified too late to prevent, creating financial risk through unexpected cost spikes and budget overruns. Staying in control requires monitoring consumption continuously and acting early to keep costs aligned with budget.
Zylo’s Consumption Cost Management Solution provides the visibility and control needed to stay ahead of OpenAI API spend. Request a demo to see how Zylo connects OpenAI API consumption to cost and prevents overages before they occur.
OpenAI API pricing is based on tokens, with separate rates for input and output. Costs vary by model, but pricing is typically structured per 1 million tokens. For example, mid-tier models may cost a few dollars per million input tokens and more for output tokens. Total cost depends on how many tokens your application processes per request and at scale.
To calculate OpenAI API costs, use this formula:
Total Cost = (Input Tokens × Input Price) + (Output Tokens × Output Price)
Then multiply by total request volume. Accurate estimates require factoring in:
Real-world costs often exceed estimates due to retries, multi-step workflows, and scaling usage.
Lightweight models (often labeled mini or nano) are typically the cheapest for OpenAI API usage. They are best suited for high-volume, simple tasks such as classification or data transformation.
However, the lowest-cost model per token does not always result in the lowest total cost. Model performance, number of requests, and workflow design all influence overall spend.
OpenAI API costs are difficult to predict because they scale with real-time usage. Cost variability is driven by:
Without continuous monitoring, costs can increase quickly and exceed expectations.
Tracking OpenAI API usage requires connecting consumption data (tokens, API calls) with cost data in a centralized system.
Platforms like Zylo provide visibility into:
This data enables teams to monitor usage continuously and take action before overages occur.
Reducing OpenAI API costs requires a proactive approach to AI cost optimization and consumption cost management.
Key strategies include:
Effective AI cost optimization focuses on reducing unnecessary consumption while improving cost visibility and control.
Consumption cost optimization is the practice of tracking, analyzing, and controlling usage-based costs tied to OpenAI API consumption.
It focuses on:
This approach enables organizations to manage OpenAI API spend proactively instead of reacting after costs occur.
Preventing OpenAI API cost overages requires proactive monitoring and AI cost optimization practices.
IT, SAM, and FinOps teams should:
With the right visibility and controls, organizations can prevent overages and maintain predictable OpenAI API costs.
Cost allocation requires mapping usage data to ownership. Organizations should:
Solutions like Zylo enable granular cost allocation, helping organizations connect OpenAI API usage to the teams responsible for it.
To optimize OpenAI API costs at scale:

Table of Contents ToggleWhat Is OpenAI API Pricing?Usage-Based Pricing vs. Subscription...
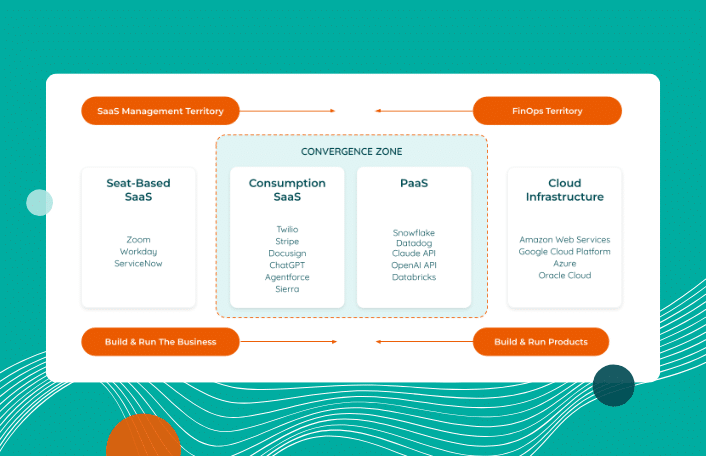
Table of Contents ToggleTL;DR: ITAM and FinOps Are Converging to Manage...